
Observing Optimizer Behavior over Search Surfaces
Visualizing the training process over various optimization surfaces. – Nov 12, 2024
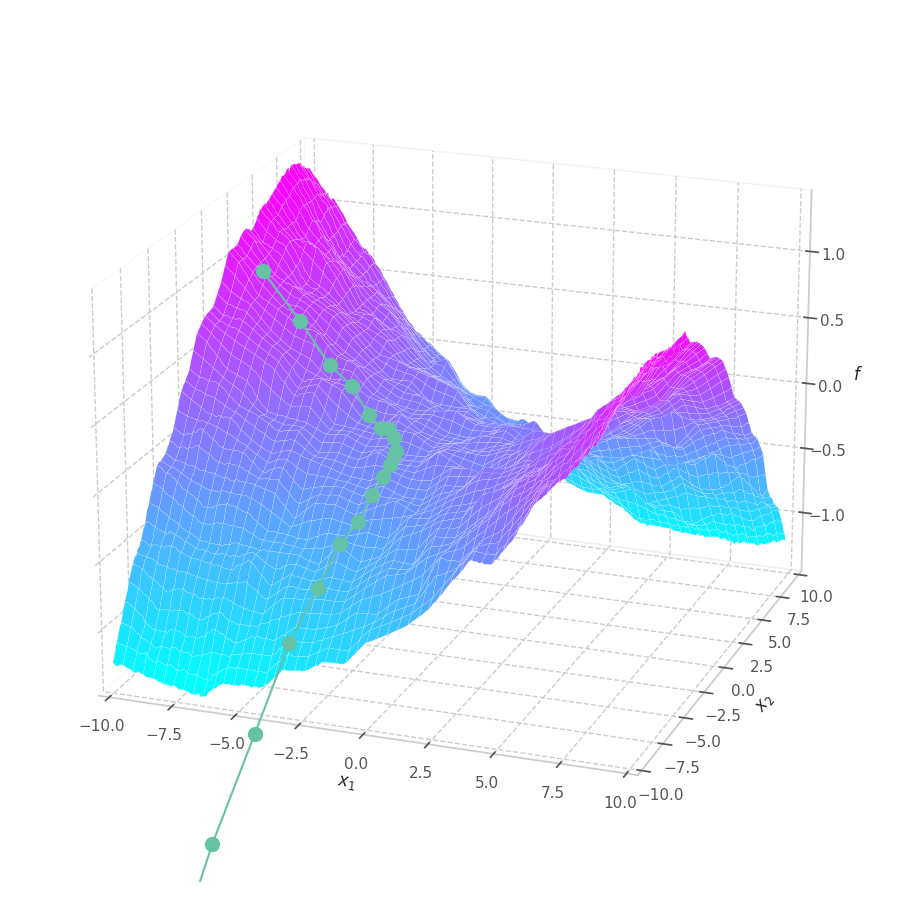
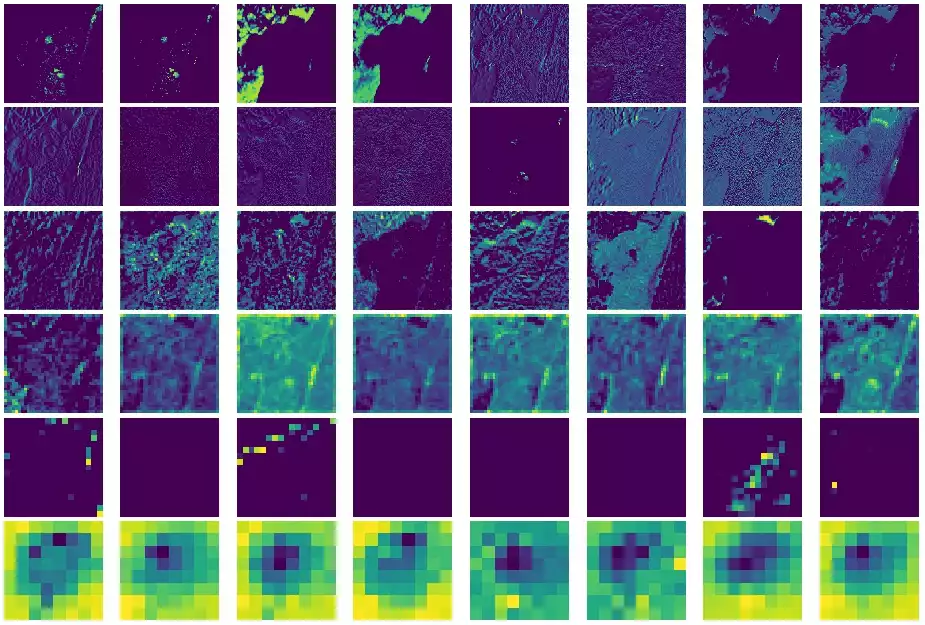
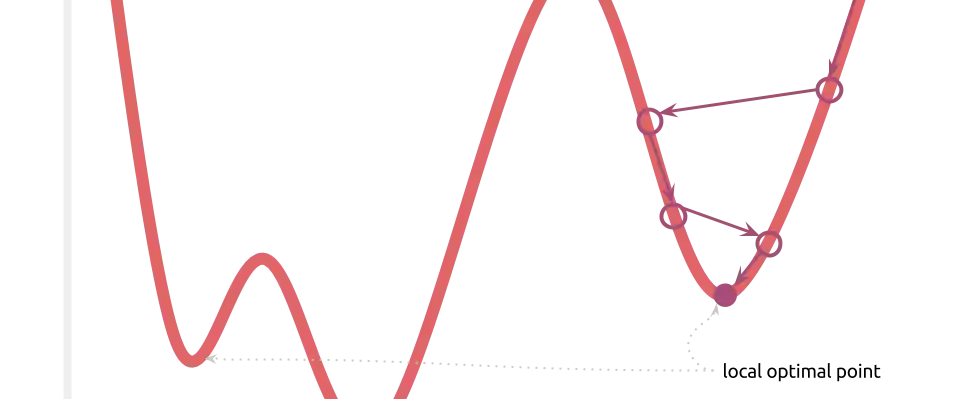
Training a Machine Learning model consists of traverse an optimization surface, seeking the best solution: the configuration of parameters θ associated to the lowest error or best fit. It would be interesting to have a have a visual representation of this process, in which problems such as local minima, noise and overshooting are explicit and better understood.
ML Optimization VisualizationActivation, Cross-Entropy and Logits
Discussion around the activation loss functions commonly used in Machine Learning problems. – Aug 30, 2021
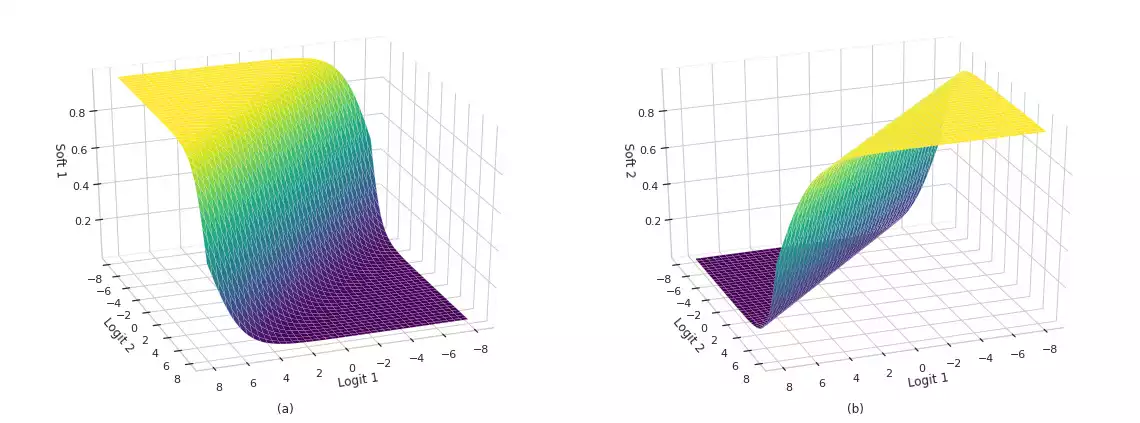
Activation and loss functions are paramount components employed in the training of Machine Learning networks. In the vein of classification problems, studies have focused on developing and analyzing functions capable of estimating posterior probability variables (class and label probabilities) with some degree of numerical stability. In this post, we present the intuition behind these functions, as well as their interesting properties and limitations. Finally, we also describe efficient implementations using popular numerical libraries such as TensorFlow.
ML Classification Multi-label Linear OptimizationSantos Dumont Super Computer
Accessing and using the SDumont infrastructure for Deep Learning research. – Aug 30, 2021

This manual details the engagement, access and usage of the Santos Dumont Super Computer. This document is profoundly based on the official support manual provided by LNCC, as well as my personal experience in the program (hence, it may not perfectly represent all cases). Its goal is to present information in a more directed manner for users that share my own profile (Deep Learning researchers that prefer the TensorFlow framework and who are familiar with Docker.
DevOps MLK-Means and Hierarchical Clustering
Efficient clustering algorithms implementations in TensorFlow and NumPy. – Jun 11, 2021
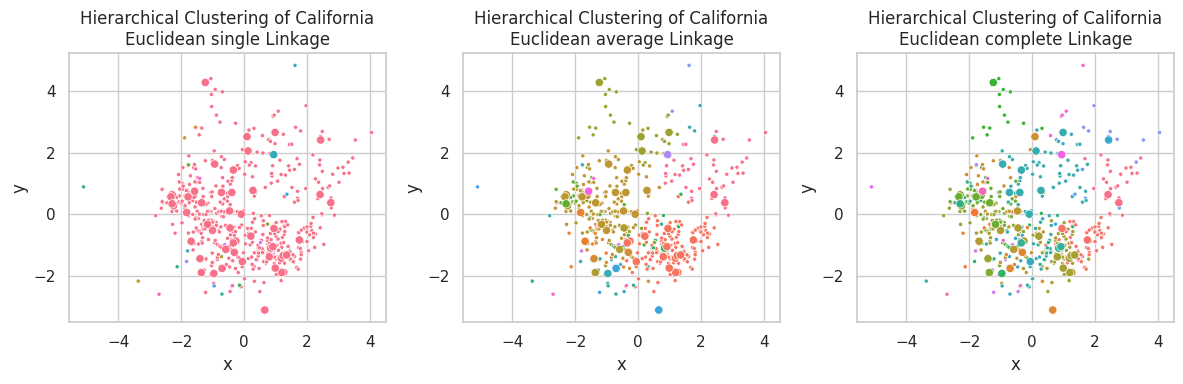
Here, our goal is to apply unsupervised learning methods to solve clustering and dimensionality reduction in two distinct task. We implemented the K-Means and Hierarchical Clustering algorithms (and their evaluation metrics) from the ground up. Results are presented over three distinct datasets, including a bonus color quantization example.
ML Clustering TensorFlowClass Activation Mapping
Explaining AI with Grad-CAM. – Mar 23, 2021

Gradient-based methods are a great way to understand a networks' output, but cannot be used to discriminate classes, as they focus on low-level features of the input space. An alternative to this are CAM-based visualization methods.
ML AI ExplainingExplaining Machine Learning Models
Explainability using tree decision visualization, weight composition, and gradient-based saliency maps. – Jan 15, 2021

Estimators that are hard to explain are also hard to trust, jeopardizing the adoption of these models by a broader audience. Research on explaining CNNs has gained traction in the past years. I'll show two related methods this post.
ML AI Explaining Scikit-Learn TensorFlowCaso de estudo sobre regressão linear (in Portuguese)
Uma descrição detalhadas dos princípios da regressão linear, a partir de um caso prático. – Sep 30, 2020
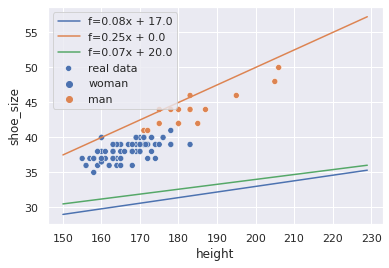
ML não é uma coisa incompreensível. Não funciona pra todos os casos e não vai necessariamente te oferecer uma solução melhor do que uma implementação bem pensada e deterministica num passe de mágica. Tem as suas utilidades. Podemos resolver problemas de uma forma relativamente simples em ambientes dinâmicos e confusos, ou onde não podemos fazer grandes suposições em relação ao seu funcionamento. Esse notebook explica um pouco sobre modelos lineares: como eles funcionam e como utilizá-los de forma eficiente. Espero que seja instrutivo e clareie um pouco do tópico pra todo mundo.
ML Regression Linear Optimization PortugueseIntrodução ao aprendizado de máquina, pt. 4
Convoluções, o início de deep-learning – Dec 24, 2017
Na parte 3, eu mostrei alguns modelos não lineares e como eles lidam com a tarefa de classificação. No geral, redes densas possuem duas ou três camadas. Isso acontece pois observa-se empiricamente que o ganho em validation loss não segue linearmente com a adição de mais camadas. Além disso, este pequeno ganho também pode ser alcançado ao simplesmente aumentar o número de unidades nas camadas já presentes na rede densa. Por quê precisamos da ideia de deep-learning e deep-models, então?
ML Computer Vision PortugueseMultilabel Learning Problems
Dealing with ML classification problems that deal where samples aren't mutually disjointed. – Oct 26, 2017

In classic classification with networks, samples belong to a single class. We usually code this relationship using one-hot encoding: a label i is transformed into a vector [0, 0, ... 1, ..., 0, 0], where the number 1 is located in the i-th position in the target vector.
ML Classification Multi-labelIntrodução ao aprendizado de máquina, pt. 3
Regressão logística, modelos não-lineares e redes artificias. – Oct 26, 2017
Apesar do nome "regressão logíca", este método remete à uma atividade de classificação. Diferente da regressão, a nossa preocupação do agente inteligente aqui não é estimar um valor, mas sim dar uma resposta: sim ou não. Como fazer isso sem perdermos o que nós aprendemos acima? Podemos utilizar uma função de ativação. Uma função aplicada sobre a saída de um modelo linear que restringe a resposta à um certo intervalo.
ML Classification Portuguese Scikit-LearnIntrodução ao aprendizado de máquina, pt. 2
Modelos lineares e otimização numérica. – Oct 26, 2017

Aqui, vamos falar um pouco sobre modelos lineares e seus funcionamentos básicos.
Exemplos são dados por trechos de código na linguagem python.
Introdução ao aprendizado de máquina, pt. 1
Um guia introdutório em Português e Python – Oct 26, 2017
Aprendizado de máquina e IA, em geral, têm ganhado muita tração nos últimos anos. Cada vez mais, indivíduos percebem as grandes vantagens das abordagens relacionadas e as utilizam para resolver seus problemas. Para você que não está familiarizado com esses termos, inteligência artificial é o ramo da ciência da computação preocupado em desenvolver máquinas que apresentem um comportamento inteligente. O aprendizado de máquina é a sub-área da IA que busca criar esse comportamento através da ideia de aprendizagem (a máquina aprende sozinha como resolver um problema).
ML Portuguese