
Activation, Cross-Entropy and Logits
Discussion around the activation loss functions commonly used in Machine Learning problems. – Aug 30, 2021
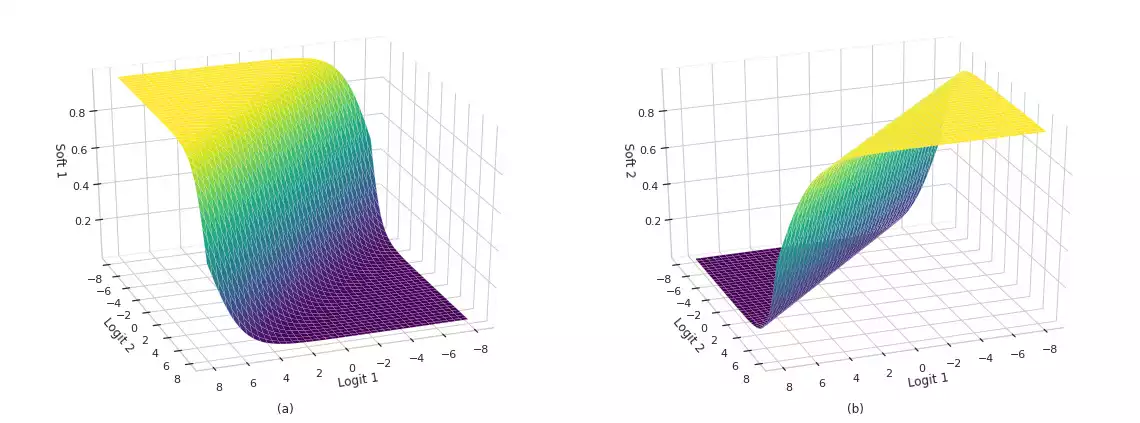
Activation and loss functions are paramount components employed in the training of Machine Learning networks. In the vein of classification problems, studies have focused on developing and analyzing functions capable of estimating posterior probability variables (class and label probabilities) with some degree of numerical stability. In this post, we present the intuition behind these functions, as well as their interesting properties and limitations. Finally, we also describe efficient implementations using popular numerical libraries such as TensorFlow.
ML Classification Multi-label Linear OptimizationMultilabel Learning Problems
Dealing with ML classification problems that deal where samples aren't mutually disjointed. – Oct 26, 2017

In classic classification with networks, samples belong to a single class. We usually code this relationship using one-hot encoding: a label i is transformed into a vector [0, 0, ... 1, ..., 0, 0], where the number 1 is located in the i-th position in the target vector.
ML Classification Multi-label