
This post will show you a different way to build web services, applications and pages. Well, at least I hope. The concept of APIs has been around for years but, statistically speaking, it’s still not so diffused as we’d like it to be. But first, I want to make it clear why I’ve opted for writing this post, which is mainly theoretical.
Most of my posts are practical, as they focus on how to do things or how to use tools. I’ve decided, however, to slow down and write the why of web APIs. The reason for this is that I understand it sucks when someone is trying to teach us a different way of doing things and we don’t even know why we should you change. Web APIs are amazing and I want to try to convince you why. Thus, this post will cover exclusively the theory behind web APIs and REST.
Since its start, the internet has come a long way. More and more, we’ve noticed a increasing pattern of migration from client native applications to web applications running on browsers (and the beginning of a new kind, hybrids apps). Easy distribution, multi-platform compatibility and contiguous connectivity are, of course, some of the features that made this transition so attractive.
We were still trying to figure it out where were we going from there, but what we did know is that although we managed to create successful web applications and services, they were self-centered machines when it came to the services and information that they offered. In other words, they’d hardly “talk” or “provide” to anything else than a human. Of course, we started questioning this limitation: as a huge share of the world’s digital content is converging to web, how do we integrate machines (in the web context) to absorb and process their own contents without human-beings constant supervision?
A “Regular” Web App
Imagine that you’re crating a service (like a e-commerce web page) and you will make it available to a set of costumers from your city. A common approach is to develop a MVC web application, with your views rendering HTML code. When you finish your app, your costumers are finally able to access your service and start exchanging data (buying or selling).
This data exchange will happen in two stages:
- Clients will make HTTP requests to the server through browsers. This server will handle the request to your MVC application, which has a component router designed to interpret the request and trigger the proper action of the proper controller. The user’s requests are often simple queries, but sometimes they involve a lot more, such as a body containing data on it.
- Your application will pre-process HTML code (to all requests, to all users) and give the result to the web server, which will send it to the browser which made the request. The browser will collect the page and analyze its content. Further requests might be made, in order to retrieve adjacent artifacts (images, style sheets, js code files, videos, audios etc).
We can easily verify two holdbacks about this approach:
- Presents a confused data representation: all data retrieving from the server is polluted by HTML tags and plain text. How can a machine understand this? Well, it must have a deep understanding over which requests are valid on your service and with what data. It then needs to be able to extract the data from the polluted HTML response. This is often achieved with data mining techniques, and considering it’s a non-deterministic process, might produce wrong answers.
- Performance: the clients’ browsers are expecting a file with HTML code, your app must inevitably build this file, which entails that all requests will inevitably pass by your app. Performance bottlenecks are usually on database queries, but we can improve performance if the server doesn’t have to assemble every goddamn HTML page on the way. Every nanosecond counts. In overall, let the server takes care only of a couple of basic tasks, such as domain logic, data and security.
That’s a lot of work if we want to create many clients (e.g.: Android or iOS apps) that absorb this service. Requiring well defined requests rules and implementing data mining algorithms… Is there a easier way?
APIs
The term API stands for Application Programming Interface. The idea of web APIs is quite similar: two machines can “talk” and understand each other if they share a common, formal language. So before thinking about creating websites, buttons and input fields, developers should implement an API layer from a well known protocol. Following applications (including a web page, if desired) should then be able to fully communicate with that layer and produce meaningful results.
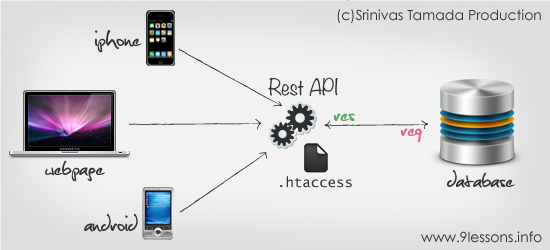
Following this idea, we soon notice some advantages:
- If the architecture that we use to program the APIs is sufficiently well known, we can integrate (with minimum or no effort what so ever) all machines in the world!
- Performance is likely to increase compared to regular web apps, as APIs usually have a reduced set of responsibilities.
- We can re-use a single back-end and only implement front-end applications for the many platforms currently existing (iOS, Android, Web browsers, native programs etc), therefore reducing work.
- We encourage people all around the globe to contribute and create stuff over our APIs. Of course, we build things over other people’ APIs.
A toy example - the future, hopefully
Imagine a world where meteorological institutes (MI), traffic control systems (TCS), cars and even traffic regulation agents (TRA) have open APIs implemented.
[caption id=”attachment_435” align=”aligncenter” width=”660”] An example of multiple APIs integrated on a graph organization, creating a meaningful anti-traffic-accident environment.[/caption]
An example of multiple APIs integrated on a graph organization, creating a meaningful anti-traffic-accident environment.[/caption]
Such connectivity creates many possibilities:
- The TCS could collect information from the cars, such as average speed, or count them. Finally, it could make this information available to all drivers.
- The TCS could also collect data from the MI and automatically adjust streets’ limit speed based on if it’s raining or foggy.
- Cars could retrieve data about these streets, such as the speed limit, length, accident rates etc, and alert the drivers if they are about to commit an infraction or suggest cautiousness in the following patches of the road.
- TRA could ticket drivers who broke the law based on the data from their cars without actually stopping them.
- TRA would be able to identify stolen cars and locate them based all data from the car and the TCS.
A real - and much smaller - example
uheer.me is a service that some friends and I developed a while ago. It’s a web app that stores channels, songs and some information about when these songs started playing. Peripheral applications can then extract those channels, songs and info and play it synchronously with the server. The idea is to throw silent disco parties or to use people’ cellphones as speakers, therefore reducing costs in buying/renting audio equipment.

Applications can make a GET request to uheer.me/api/Channels, which produces the following response:
curl http://uheer.me/api/Channels
[
{
"Id": 1,
"Name": "Blue",
"Author": {...},
...,
"Loops": true,
"CurrentId": 1,
"CurrentStartTime": "2015-08-24T12:33:02.81",
"DateCreated": "2015-07-15T19:56:30.57",
"DateUpdated": "2015-08-24T12:34:49.34",
"DateDeactivated": "2015-08-24T12:34:49.34"
},
...
]
This is, in fact, all the data about the music channels registered in uheer. With CurrentStartTime, CurrentId and the current time at the server (retrieved from the route uheer.me/api/Status/Now, applications can infer in which position the song currently is and play it synchronously with the rest of the party. In our tests, we achieved multiple devices synchronized by 20ms!
REST
#1 In computing, Representational State Transfer (REST) is a software architecture style for building scalable web services. REST gives a coordinated set of constraints to the design of components in a distributed hypermedia system that can lead to a higher performing and more maintainable architecture. - wikipedia
Offering a completely different approach from SOAP, Representational State Transfer (REST) quickly became the most popular architecture used for building web APIs. Betting on simplicity, it allows the creation of beautiful APIs, generic enough to be understood by a large share (if not all) of systems.
REST involves a couple of core concepts:
- Client-Server: shortly, a separation of concerns. The server is responsible for data storage, security, domain logic etc. Overall, it will focus on handling data instead of concerning about user interfaces or presentation, which will be tackled by the many clients that absorb the REST API. This clearly improves features such as scalability, simplicity, portability and maintainability.
- Stateless: the server doesn’t hold different, complex states. The communication with its peers is given through self-contained, self-explanatory requests and responses. Security should stop being offered by sessions (slow) and be implemented using tokens and protocols such as oauth (faster). The state, if any, will be stored by the clients, which have much less processing to do than the server.
- Cacheable: the server must implement partial or complete cache in order to increase performance when trading messages with its clients.
- Uniform interface: the server must implement a uniform interface with which the clients may interact. The server and the clients can then be implemented independently. This represents a considerable reduction of effort when building applications, as a single server may be re-used by different platforms. E.g.: a social network behind a REST API which can be easily absorbed by different platforms (web browsers, Android apps, iOS apps, native apps).
- Layered System: the API is composed by hierarchical layers, which are all seamless to client apps. This is ideal for component reuse, load balancing or encapsulating legacy code.
- Code on demand (optional): the server may transfer code to a client, temporarily extending its functionality.
REST’s practical concepts in web services
Resources and end-points
REST scaffolds over the concept of resources: a entity or collection of entities that can be retrieved, manipulated and then stored again. A resource will have an end-point (an URI) associated with it.
Examples
- Channels, uheer.me/api/Channels *
- Me, graph.facebook.com/me
Endpoints may contain parameters related to the resource:
- Album, graph.facebook.com/v2.4/{album-id}
- AlbumPhotos, graph.facebook.com/v2.4/{album-id}/photos
#2 uheer is NOT a REST API, as it violates many of the concepts presented above. It still a good example, though, as it’s also divided into resources.
Methods
Clients can manipulate resources by making HTTP requests to their respective end-point, specifying a method. This methods are the same as defined by the HTTP protocol:
- GET: retrieve the resource.
- OPTIONS: will retrieve the valid options available for the given end-point.
- HEAD: returns the same response as GET, but without a body.
- POST: create a resource.
- PATCH: update a resource patching it with the data passed in the request.
- PUT: updates a resource replacing it with the data passed in the request.
- DELETE: deletes a resource. Pretty obvious.
Examples
Making the following raw HTTP request will create a new product with the specified data.
curl -POST http://.../Products \
--data '{"name":"A Nice Product", "price":1.42}'
Or the equivalent in Python:
import requests
requests.post('http://.../Products',
json={'name': 'A Nice Product', 'price': 1.42})
Or in Angular.js (perfect for web sites, check out more here!):
Product = $resource('http://.../Products');
new Product({name: 'A Nice Product', price: 1.42}).$save();
Responses
Each interaction with the server will generate a response. For instance, making the following request to api.github.com/users/lucasdavid:
GET /users/lucasdavid HTTP/1.1
User-Agent: curl/7.35.0
Host: api.github.com
Accept: */*
Will result in:
HTTP/1.1 200 OK
Server: GitHub.com
Date: Wed, 07 Oct 2015 02:33:46 GMT
Content-Type: application/json; charset=utf-8
Content-Length: 1309
Status: 200 OK
...
{
"login": "lucasdavid",
"id": {ID_NUMBER},
"avatar_url": "https://avatars.githubusercontent.com/u/{ID_NUMBER}?v=3",
"gravatar_id": "",
"url": "https://api.github.com/users/lucasdavid",
"html_url": "https://github.com/lucasdavid",
"followers_url": "https://api.github.com/users/lucasdavid/followers",
"following_url": "https://api.github.com/users/lucasdavid/following{/other_user}",
"gists_url": "https://api.github.com/users/lucasdavid/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lucasdavid/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lucasdavid/subscriptions",
"organizations_url": "https://api.github.com/users/lucasdavid/orgs",
"repos_url": "https://api.github.com/users/lucasdavid/repos",
"events_url": "https://api.github.com/users/lucasdavid/events{/privacy}",
"received_events_url": "https://api.github.com/users/lucasdavid/received_events",
"type": "User",
"site_admin": false,
"name": "Lucas Oliveira David",
"company": null,
"blog": null,
"location": "City Name, State Name, Brazil",
"email": "email@company.com",
"hireable": true,
"bio": null,
"public_repos": 21,
"public_gists": 0,
"followers": 15,
"following": 10,
"created_at": "2018-04-01T08:24:40Z",
"updated_at": "2018-10-01T18:36:59Z"
}
A HTTP response contains a header and the body. In the header, we can find metadata related to the server’s response itself, such as the timestamp in which it was processed, or the status-code. REST re-uses these default codes to indicate the status of the request. Clients must, of course, be able to understand them. Bellow is a list with some:
- 2xx
- 200 Ok: the request was successful.
- 201 Created: the resource was created.
- 204 No Content: The request was successful and the response is empty.
- 4xx
- 400 Bad Request: request couldn’t be understood.
- 401 Unauthorized: authentication is required but it wasn’t provided.
- 403 Forbidden: the server refuses to fulfill the request. May happen because of lack of privileges.
- 404 Not Found: the requested resource was not found.
- 500 Internal Server Error: the server cannot fulfill the request because of an internal error.
The body, on the other hand, may be empty or contain any data, usually represented in JSON. For instance, in the request above, it contains information about my GitHub account.
Who implement Web and REST APIs?
Many people! Bellow there’s a list of the most popular ones:
How do I start coding my own?
The ideal is to always reuse already existing implementations. Some famous frameworks that help you in the creation of REST and web APIs:
To consume an existing API, any device, programming language or technology able to communicate HTTP will do just fine. If you need a classic web browser application, check out AngularJS, which was built to absorb REST APIs and create single-page web apps with JavaScript.
Conclusion
REST is becoming more popular each year, as people realize how this architecture benefits applications by improving performance, standardizing data representation and allowing ease integration between an great number of applications.
I hope this introductory post has pointed out and convinced you about the advantages of programming web and REST APIs beneath your web pages.
Finally, if you made it this far and is still not bored, check out this REST framework which I have recently started. grapher was made over Flask and it might help you to start projects stupidly fast!