
Aprendizado de máquina e IA, em geral, têm ganhado muita tração nos últimos anos. Cada vez mais, indivíduos percebem as grandes vantagens das abordagens relacionadas e as utilizam para resolver seus problemas.
Para você que não está familiarizado com esses termos, inteligência artificial é o ramo da ciência da computação preocupado em desenvolver máquinas que apresentem um comportamento inteligente. O aprendizado de máquina é a sub-área da IA que busca criar esse comportamento através da ideia de aprendizagem (a máquina aprende sozinha como resolver um problema).
Nesta sequência de publicações, vou apresentar alguns elementos da abordagem conexionista do aprendizado de máquina (onde as redes neurais estão) e como elas podem ser construídas na pratica. Espero que o leitor aproveite este conteúdo, uma vez que muito do que é escrito na área está em língua extrangeira ou é de difícil acesso. Por fim, é importante dizer que este conteúdo de nenhuma forma substitui – nem tenta – o conteúdo presente em livros da área, que apresentam os conceitos de forma mais gradual, formalmente definidas e claras.
Por quê aprendizado de máquina?
Supondo que IA e ML sejam conceitos completamente desconhecidos, como você resolveria problemas quaisquer utilizando computadores? Usualmente, uma representação computacional do problema é formada. Os objetivos são então definidos e a lógica que conecta as representações aos objetivos é implementada através de um algoritmo.

Por exemplo, suponha que você queira criar uma plataforma onde Magic: The Gathering possa ser jogado. Você precisaria definir:
- representação do jogo: classes para jogadores, cartas, jogos, eventos
- objetivos: executar partidas, jogar cartas, atacar etc
- lógica: todo código que se utiliza da representação a fim de realizar os objetivos, como infraestrutura, métodos, testes
Apesar de ser um pouco difícil e chato, essa tarefa é completamente factível. Tenho um exemplo funcionando aqui, na verdade: github.com/lucasdavid/jmagic.
Mas o que acontece quando não sabemos exatamente como ligar as representações aos resultados desejados? Isto é, como construir o algoritmo que nos levaria à resposta?
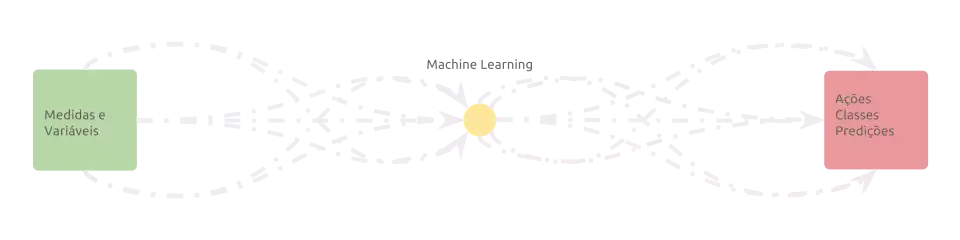
O aprendizado de máquina supervisionado clássico se preocupou em resolver esse tipo de problema. Grosseiramente falando, a ideia é criar um modelo (uma função) que associa estocasticamente todas as representações a todas as saídas possíveis, admitindo um alto nível de liberdade.
Num primeiro momento, o modelo não é muito útil. Alimentá-lo com uma
representação qualquer do problema resulta em uma saída aleatória. Entretanto,
podemos melhorar seu comportamento com treinameno. Ao apresentar pares
(entradas, saídas) que representem comportamentos desejados, o modelo pode
“por si só” refinar seus parâmetros a fim de imitar as associações apresentadas.
Uma vez treinado, um modelo entra no período de teste. Neste, alimentá-lo com
entradas produz saídas que imitam as vistas do treino. Se a aproximação é
boa, você conseguiu resolver o problema. Senão… Bom, isso é outra história. :-)
Na parte 2, vou mostrar um modelo linear simples e como ele funciona.